
Can AI take over chemistry (and chemists)?
Published:
We have all been hearing the following auguries quite frequently in recent years -- "Machines are going to replace humans in all the tasks that you could imagine?", "Artificial Intelligence is going to solve all the problems (but invent several others) that the human civilization currently suffers from!" and my personal favorite, "You throw anything at the ML software, and it will spit out the correct answer; it's like magic!" Though all of these (scandalous) statements have some truth in them, they are not at all helpful in addressing the question that a non-ML scientist often has at the back of his mind -- could she be replaced as conveniently by algorithms as it is claimed so often?
The short answer to this is no, or in fact, I should say never! No matter how complex or with how many billions of training parameters, there could never be algorithms that could completely replace an expert chemist. After all, the intelligence part of AI is still artificial. The more you look into it, the more pronounced the realization that they are not even close to even fractionally mimicking the human mind's capabilities. If this doesn't sound convincing and would like to know the more extended version, read on.
Though the central question that I try to answer here is whether a human chemist could be replaced by machine learning-based systems, the same, in my opinion, applies to all the engineering and scientific disciplines. This post's premise is based on our series of works where we build a chemistry-informed ML system that predicts the outcomes of organic chemical reactions -- both in the forward and the reverse (retrosynthesis) direction. There is no requirement for the chemist to perform any laboratory experiments whatsoever. Our article describes this approach in much more technical detail than I would be covering in this post. If you or your institution does not have access to the journal, please reach out to me, and I would be happy to share the full-text pdf version of the article.
Organic chemical reactions
Organic reactions are those that primarily involve organic compounds, consisting of molecules that are predominantly composed of carbon (C) and hydrogen (H) atoms, with the optional presence of certain other elements such as oxygen (O), nitrogen (N), chlorine (Cl), bromine (Br), and so on. A vast majority of the compounds on earth are hydrocarbons, with their immense abundance playing a significant role in global and local phenomena (climate change?). Such reactions occur through a series of reactions that are highly dependent on the type of molecules under consideration and the reaction environment, often giving rise to highly complex compounds in just a few steps. Moreover, the selectivity of the products changes significantly as the reaction conditions change. As a result of these factors, organic chemistry poses several challenges to anyone who attempts to use computational methods for modeling them. The difficulty increases several-fold if the underlying chemistry information is completely ignored. Here are two reactions that demonstrate how simple and complex organic reactions could become, depending on the participating compounds.
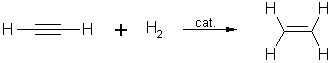
Figure 1: A simple hydrogenation reaction for the formation of ethene from ethyne
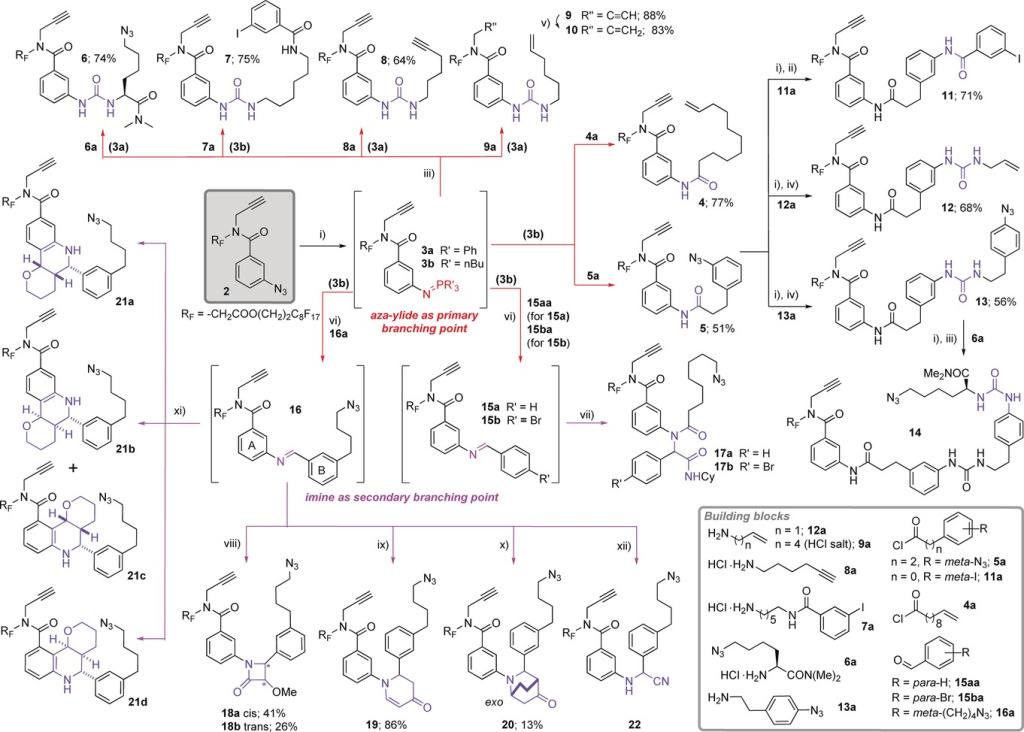
Figure 2. This is how complex an organic chemistry reaction could get. Image from F. Nie, D. L. Kunciw, D. Wilcke, J. E. Stokes, W. R. J. D. Galloway, S. Bartlett, H. F. Sore, D. R. Spring, Angew. Chem. Int. Ed. 2016, 55, 11139
Conventional reaction prediction approaches
Conventionally, most of the reaction prediction work is guided by the existing reaction mechanisms known to chemists. These mechanisms are selected based on how a molecule gets manipulated based on the class of reactions that it might participate in across all the possibilities. Clearly, the process gets extremely complicated as more complex compounds are involved. Adding to the problem, there is a dire shortage (relatively) of expert chemists in the scientific community who could devote their valuable time to sifting through all the possible chemical pathways to discover novel reactions. Instead, they are more dependent on their experience, chemistry knowledge, and intuition that guides them in the right direction. However, wouldn't it be beneficial for the entire scientific community if there were a helping hand in the form of a computational tool that could do most of the work and leave the creative aspects of the task to the chemist?
Again, machine learning to the rescue!
Isn't it incredible how useful they seem to be, yet we all despise them because of their lack of transparency from a human's perspective? Isn't this our limitation to understand the systems that work so well and make predictions on data points outside the training set and a reasonably high degree of accuracy? I'll defer this discussion to a later post and stick to the reaction prediction problem in the interest of most readers' attention deficit.
Machine translation and reaction prediction
Our motivation to use a machine translation approach to the reaction prediction framework came into existence because of the stark similarities between the natural language that we use to communicate in our daily lives and the language of chemistry that the chemists use in their daily lives (in addition to natural language, of course!). Just as natural language has sentences and words as the atomic units in a sentence that convey a given meaning, the language of chemistry analogously has molecular representations (H2O, CO2, C2H5OH) with the individual characters as the atomic units that convey information on the constituent elements and their stoichiometry. Thus, using a machine translation framework made complete sense, and we hypothesized that this would give rise to a new paradigm in computational reaction prediction approaches.
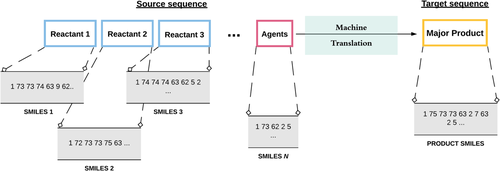
Figure 3: Modeling a chemical reaction prediction task as a machine translation problem. Image from Mann, V. and Venkatasubramanian, V. (2021)
The next question was, how do we incorporate chemistry knowledge in the system? We again turned to the analogy between natural language and chemistry to look for an answer. Quickly, the natural language analogy's natural extension seemed to be the grammatical or syntactic structure of natural language sentences -- grammatical rules that formalize the construction of sentences (molecular representations) from their respective atomic units. All the existing works in reaction prediction have ignored this stark analogy that fundamentally defines the structure of the high-level constructs from the lower-level units. We hypothesized that including such information in the machine translation frameworks would significantly help the model learn the grammar instead of hoping that the model would learn (or memorize) it based on the training set. Moreover, such a grammar-based framework would ensure that the predictions made using such a framework would be highly likely to follow the grammar-rules themselves and therefore be syntactically correct, i.e., water is more likely to be predicted as H2O instead of 2HO or OH2. However, all of them have the same stoichiometry.
The grammar rules for natural language and a text-based representation of molecules (SMILES notation) are shown in the following figure. The stark contrasts between the non-grammatical and grammatical representations seem apparent. The molecular formula-based representations C3H6 contains the least amount of chemical information and hence, is out of the question when considering representations for use in complex matching learning architectures.
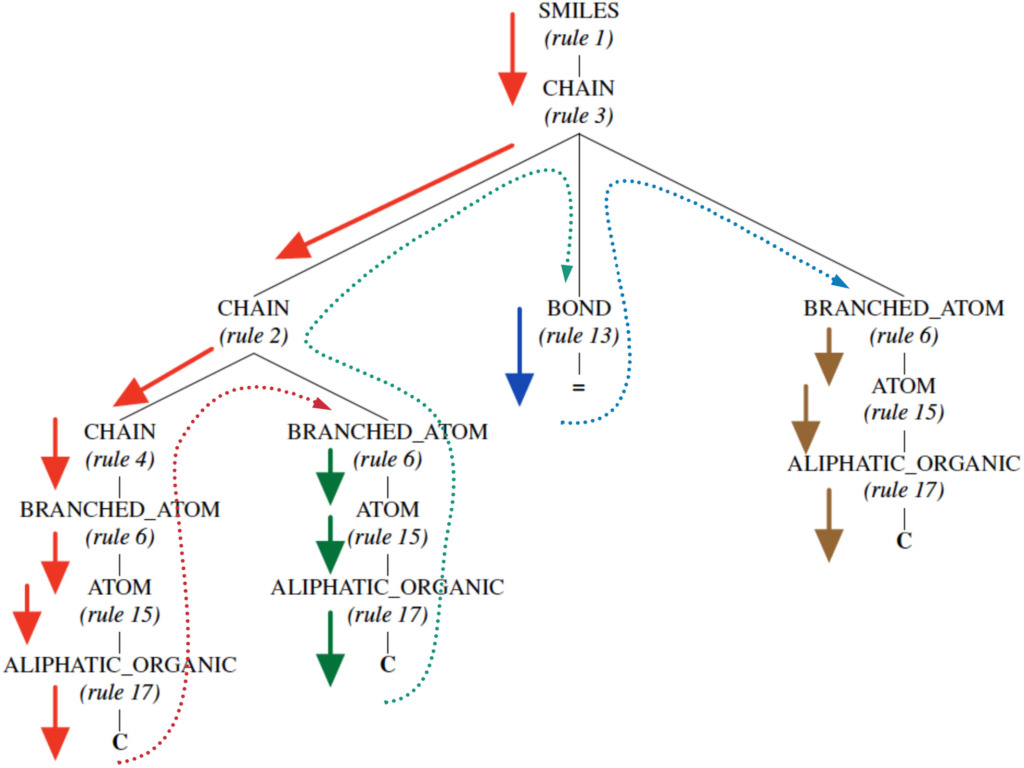
Figure 4: The parse‐tree obtained for propene with the simplified molecular‐input line‐entry system (SMILES) representation as CC=C using the representative grammar. The sequence of production rule indices obtained while parsing the above tree corresponds to the grammar representation and is given as 1, 3, 2, 4, 6, 15, 17, 6, 15, 17, 13, 6, 15, 17. Image from Mann, V. and Venkatasubramanian, V. (2021)
We, therefore, proposed these newer representations that incorporate the underlying structure. Without going too much into technical details, imagine that each text-based representation is obtained by following a set of grammatical rules applied sequentially to get the corresponding tokens. These rules and their sequential application could be represented using a tree, as shown above. The grammar production rules are extracted from these trees by parsing them in the indicated manner, which now becomes the new representations that incorporate all the additional structural and grammatical information underlying the molecule.
Our approach gave promising results. For over 80% of the unseen reactions, the model resulted in an exact match with the reaction's correct product. Moreover, of all the predictions on the test dataset, 99% of the predictions were syntactically correct, indicating that our model learned the underlying SMILES grammar, similar to a person learning the English language's grammatical constructs to ensure she forms grammatically correct sentences. Further analysis revealed that the average similarity of all the predictions was over 95%, meaning that even the incorrect predictions were very close to the ground truth and differed only by a slight mismatch. Finally, true to this post's spirit, we compared the performance against human organic chemists, and the results were surprising yet again -- the model beat them across all the reaction types. The following figures show the comparison and the incorrect predictions that were still very close to the ground truth.
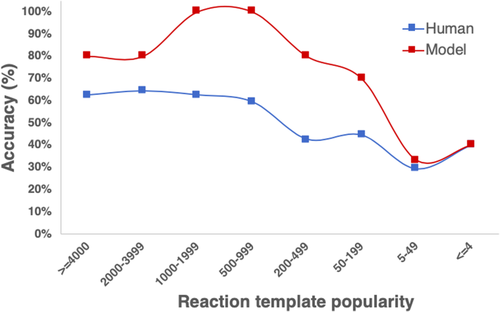
Figure 5: Prediction accuracy of the model and the average accuracy of human chemists versus reaction template popularity. Image from Mann, V. and Venkatasubramanian, V. (2021)
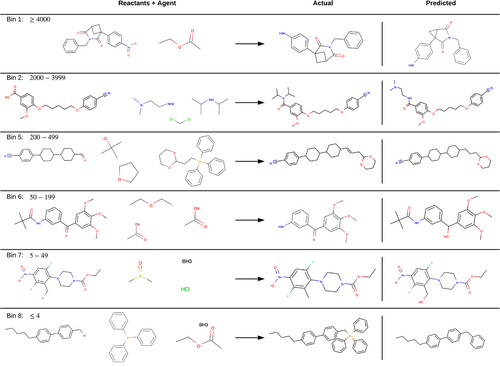
Figure 6: Some of the reactions in the human chemists’ dataset that were predicted incorrectly by our model. Even the incorrect predictions share a structure very similar to the actual product of the reaction. The bin popularity along with their frequency of appearance in the database is indicated for each reaction. Image from Mann, V. and Venkatasubramanian, V. (2021)
What does this mean?
Coming back to the same question -- would the rapid development and improvement of such systems eventually replace the human experts and obviate the years of hard-earned experience? Certainly not! At best, such systems would help an expert chemist make faster (and possibly better?) decisions by cutting short the experimentation cycle and serving merely as a 'suggestions-providing system'. There is, however, a lot of optimism around building such automated chemistry modeling and prediction systems, with many leading corporations betting big on this. But would anyone prefer entirely relying on such systems and getting rid of all the chemists? Could we get rid of all the chemistry textbooks and treat chemistry as yet another data-rich field like computer vision or robotics?
The answer to this would be clear when we consider the following question -- would you take a vaccine that is completely designed using ML algorithms, with little to no involvement of human experts, but seems promising on all the possible data-driven metrics? Even if the test-set accuracy is nearly perfect, would you share the same confidence as the data scientists who designed the model? In my opinion, that is the litmus test for determining whether we are at the stage of replacing chemists and chemistry with AI models. At present, we are (really) far from it!
